Three AI Design Patterns of Autonomous Agents
One of the hottest topics in AI over the past year has been the use of Large Language Models (LLMs) as reasoning engines for autonomous agents.
The enhanced reasoning capabilities of models such as GPT, Claude, Llama and Gemini have set the stage for the creation of increasingly sophisticated and powerful agents.
I’ll go over the core concepts to building agents as well as three different design patterns and how to implement them:
- ReAct Agent
- Task-Planner Agent
- Multi-Agent Orchestration
Each pattern is agnostic of language and framework and will address different concepts as well as design complexities that arise between each.
Core Concepts
Before jumping into each pattern, let’s first understand the common elements utilized across these designs.
Prompting
A fundamental component in building agents is the prompting techniques applied to the language model.
The typical method for creating prompts involves incorporating intermediate reasoning steps with the model, this is commonly referred to as Chain of Thought (CoT) prompting. This technique allows the model to solve complex problems incrementally.

By introducing intermediate steps, the model can generate more accurate answers compared to other methods such as zero-shot prompting.
Another technique, known as Reasoning and Acting (ReAct) prompting, is an extension of CoT but includes actionable steps that can be executed within an environment.

In the example given, the model determines actions to take which return information that is then passed to the model through in-context learning to help solve the problem.
If we attempted to solve this without the factual context from the actions, the model would likely hallucinate an answer.
Other techniques like self-reflection (Reflexion) is a way to introduce verbal reinforcement to the model to self-reflect previous steps taken. All of these techniques involve breaking down the prompt into multiple steps.
Persona
A way to keep the model on topic and generate the best answers is through the use of a persona. This is often set as the initial prompt (also known as the system prompt) used with the agent to limit and keep the output focused on the type of problem you want the model to solve.
For example, for an agent that focuses on writing code, assigning the persona of an “expert programmer” can improve reasoning and keep the model’s output limited to programming-related topics.
Tools
Agents need a way to perform actions with their environment. This can be done through the use of tools, similar to how we (as humans) use tools to help solve our own problems, agents can also use tools that we define.
For an agent, a tool is part of our program that the model learns to use through in-context learning. This takes a schema, using a structured input and output that the model is able to reason potential parameters for. By using the model like a natural language reasoning engine, we attempt to generate actions from the semantics of the request.
Structured Input & Output
When prompting models we typically use natural language but when building agents we need a way to “marshal” intent to and from our application memory. One common way to do this is using structured language that the model has been trained on. This is typically JSON, although other structured languages can also be compatible with many models.
Memory
The agent needs a way to track what has been done between each step. We can think of this like a “scratchpad” where the agent will take notes on what its done so far. This can be short-term memory (usually stateless) or long-term memory (stateful).
Workflows
To program and orchestrate the behavior of the agent with your application logic, a workflow is required. There are various types of workflows such as directed acyclic graphs (DAGs), finite state machines (FSM), and control flow graphs (CFG).
Here is some general guidance for choosing the right workflow:
- DAGs: Suitable for programming a directed series of steps that don’t require backtracking or cycles.
- FSMs: Ideal when programming with a finite number of states, transitions, and actions without directed flow.
- CFGs: Best for programming a dynamic series of steps where conditions determine the flow, allowing for cycles and backtracking.
In this article, I will primarily cover FSMs as a way to program agentic workflows. However, different techniques can serve various purposes when implementing agents. The problem you’re trying to solve with your agent should guide the type of workflow you choose.
Notable frameworks for building custom workflow orchestration include:
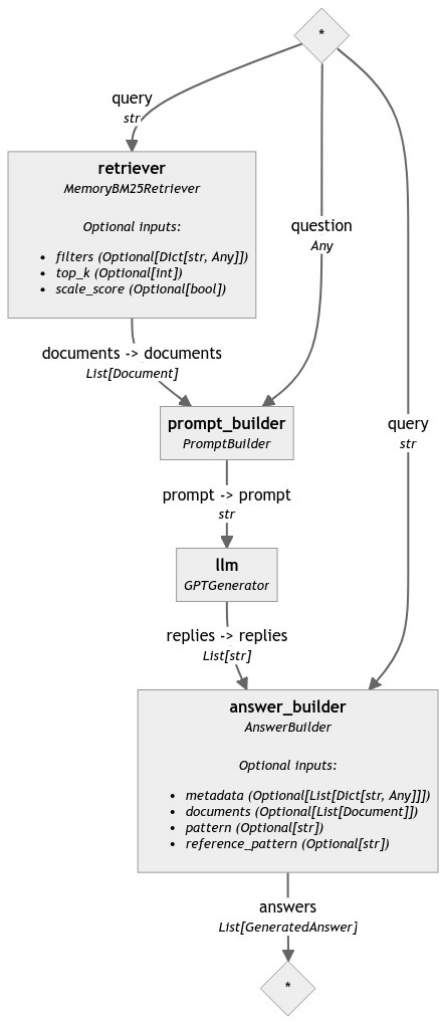
- Haystack — an end-to-end LLM framework that allows you to build applications powered by LLMs, Transformer models, vector search and more. Haystack focuses on building DAG’s. Example of retrieval augmented generation (RAG) as a DAG:
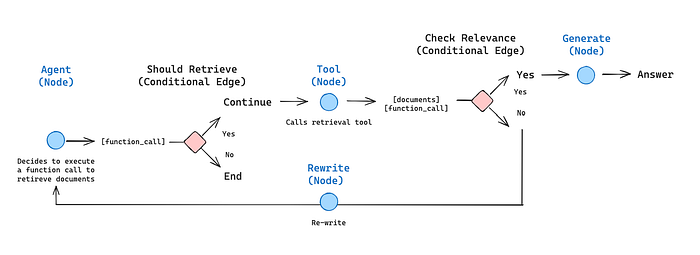
- LangGraph — a library for building stateful, multi-actor applications with LLMs, used to create agent and multi-agent workflows. Compared to other LLM frameworks, it offers these core benefits: cycles, controllability, and persistence. LangGraph allows you to define flows that involve cycles, essential for most agentic architectures, differentiating it from DAG-based solutions. LangGraph focuses on building CFGs. Example of agentic RAG with a cycle:
- assemble — an experimental framework written by me for building Agents through the use of an FSM.
ReAct Agent
The ReAct agent specializes in reasoning and action handling within its environment.
In this pattern, we can implement different ReAct prompts as specific states in a FSM. This approach ensures that the agent’s responses are consistent and relevant to the current context or task at hand.
Each state can represent various properties, including:
- a prompt for the model and,
- a handler for mapping application logic to and from the model
The main states used in ReAct are:
- Thought — addresses the problem given the previous actions taken and determines the next step to take.
- Act — determines the correct tool to use and the correct input for that tool.
- Observe — summarizes the behavior from the action to the memory.
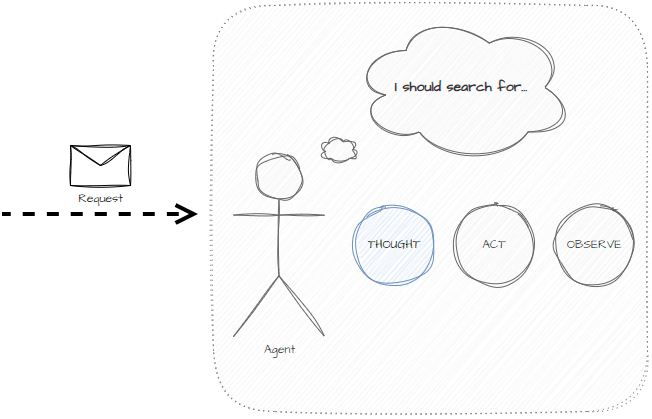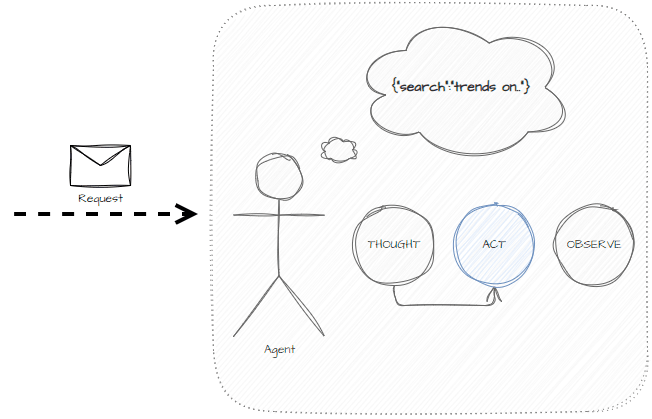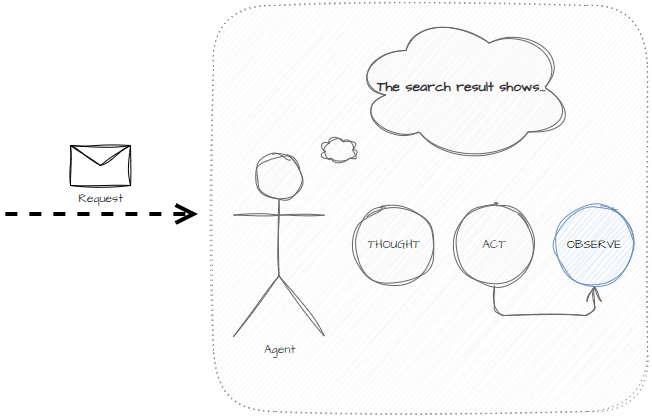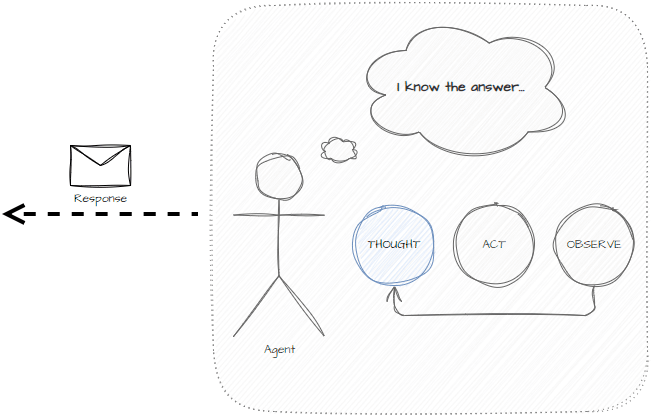
The benefits of implementing the agent this way are:
- predictability
- tasks are isolated from other states
- easy to troubleshoot
- easy to add new states
Potential problems include:
- prone to getting stuck in loops
- can get side tracked or lose focus from the original request
A simple FSM ReAct agent can be written in Python, for this example lets assume the LLM backend is implemented elsewhere and the agent has tools and memory.
The example uses a StockTicker price tool to get factual information on ticker prices. The agent can reason when the question is asking about a particular ticker and use the tool. It’s possible to add in additional tools to ask more complex questions. Each handler contains a prompt and the correct structured input and output parsing using Pydantic to create JSON schemas.
This implementation isn’t complete but addresses a simple way to build this agent.
Additional improvements would be:
- to add context-window awareness to the memory. If the tool output or memory grows too large, you would need to compress it. We can figure out the length of our memory by tokenizing everything first to see whether the memory is too large. If it is, then you can do summarization, truncation or another technique to reduce the total tokens in the memory.
- adding control-flows for context cancellation or escaping from loops.
One of the advantages to implementing the agent with an FSM is that it isn’t limited to just ReAct states. Additional states can be defined for more complex behaviors. This pattern allows for a solid foundation and extensible basis to building agents.
Task-Planner Agent
The task planner is an agent which defines a concrete plan on what needs to be done and attempts to work through that plan in multiple steps. It’s an extension of the ReAct agent by introducing a planning step.
The plan will consist of tasks where each task is an isolated piece of work. In the below example, the task planner defines a set of tasks and will work through them one at a time.
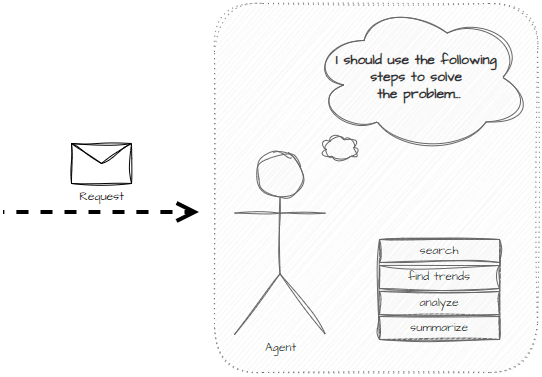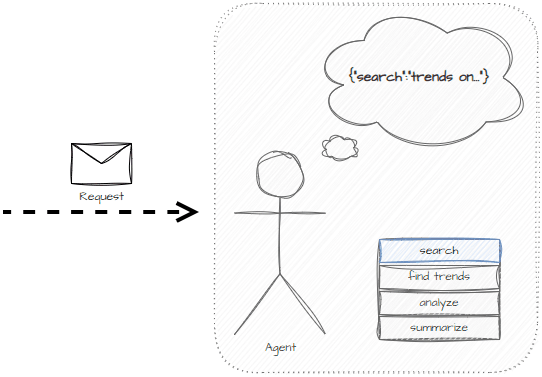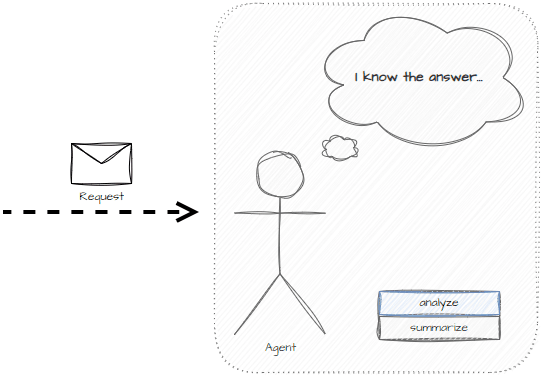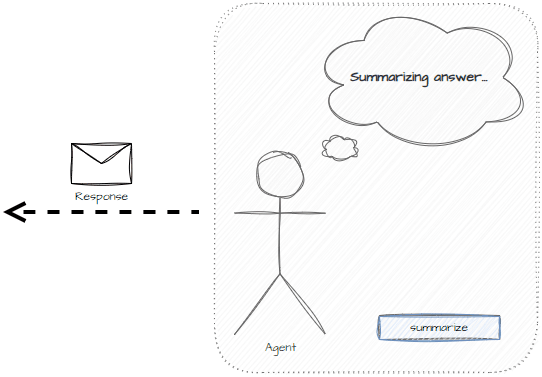
We can test the planning prompt for generating tasks using the OpenAI playground with GPT 4 Turbo.

The model is able to create isolated tasks on what might need to be done.
Like the ReAct example, the design for this agent can use an FSM as the basis of its implementation. The planning step would occur as a new state and the action state would instead pop from the stack of tasks and observe the output from the tools.
The benefit of this pattern is that work is planned upfront rather than continuously like the ReAct agent. This defines intermediate steps early that can help reduce the chance of getting stuck in a loop, but it’s not guaranteed.
This also comes with some problems where the agent might initially make a mistake in the plan which might cause errors throughout the tasks and require backtracking and generating new tasks. There’s a chance tasks are impossible to solve like invalid tool usage which requires a new plan and starting over. This can be an expensive mistake, therefore planning should be limited to tasks which are easily predictable.
This type of prompting is similar to an early project that got popular called AutoGPT which uses a task queue to breakdown the problem into small pieces of work. This was one of the first projects to implement agentic like workflows with language models.
Multi-Agent Orchestration
When asking agents complex tasks, it’s often difficult to scale the behavior of the agent correctly. This is a limiting factor for a number reasons, such as the persona, too many types of actions or too many states on what the agent could do.
One approach to solving this problem is by separating responsibilities of the agent and introducing another reasoning step for communication with other agents.
By giving agents the ability to communicate, they can delegate work through orchestration of tasks. This approach is similar to a delegation-like pattern.
Rather than having a single agent that does everything, we can define agents that specialize in solving specific problems that also have different implementations.
Instead of having the agent figure out who to communicate with, we can introduce an orchestrator that can both supervise and route between agents to get the best desired output based on the task.
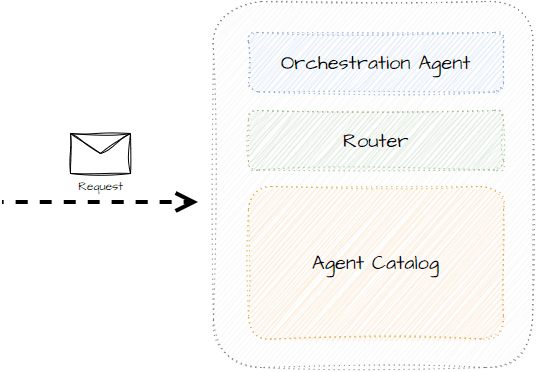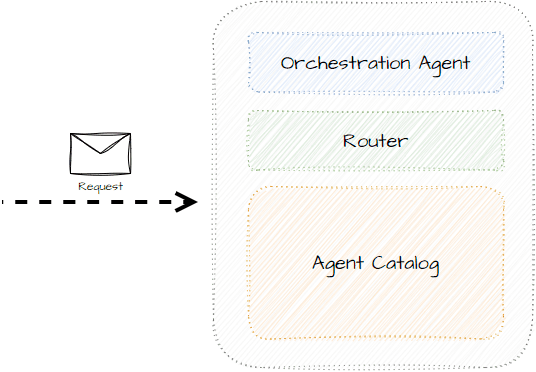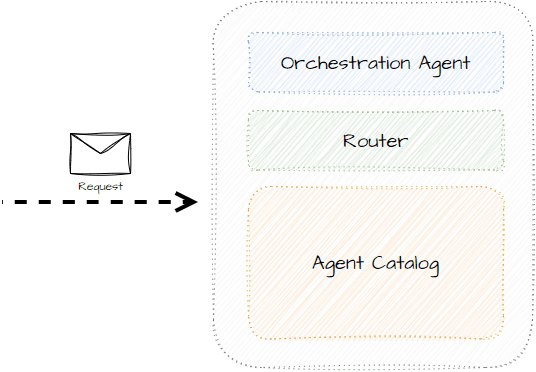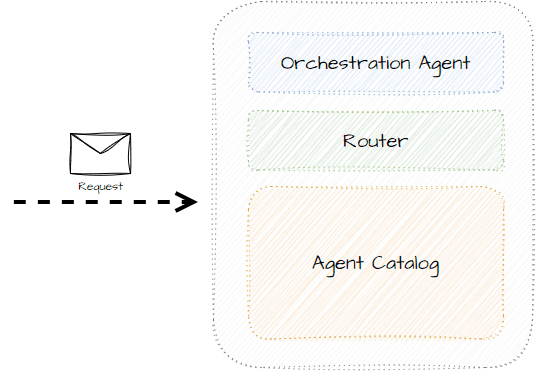
By separating and abstracting communication, agents don’t need to know how a task is solved.
Like the previous examples, an orchestration step can be defined using the FSM and the previous prompting techniques.
Examples of Multi-Agent Implementations
Multi-agent implementations have been growing popular in the community to better scale tasks.
One such project is CrewAI where you can define the persona of your agents, their capabilities and then create a “crew” where the agents work together to solve the tasks.
Example code from CrewAI:
OpenAI also introduced a similar feature to this in ChatGPT by allowing users to message multiple GPTs in a conversation. A GPT is an autonomous agentic feature in ChatGPT that has reasoning capability and tool usage. This allows users to potentially use GPTs which have different personas, prompts and tools to answer complex questions in a multi-agentic way for a single conversation.
I created a simple conversation to demonstrate this idea. First I used a GPT for writing, then the official DALL-E GPT and last a custom GPT I wrote. Each GPT has a different system prompt and tools but can be used to solve different problems together.

Distributed Architecture for Agent Communication?
The separation of agent responsibility also allows for the ability to create a more complex architecture for a distributed agent network. Remote communication of agents would give a few interesting benefits:
- ability for agents to run on different hardware and networks
- be written in different languages or frameworks, agnostic to underlying implementation details
- scale for different workloads
- broadcasting work across a pool of agents for fanning out work
- discoverability for finding agents to perform tasks
There could be many different approaches to implement this, but one method is with a distributed Actor model. The Actor model is typically a message passing concurrency methodology but some frameworks support remote communication.
An actor can: make local decisions, create more actors, send messages, and determine how to respond to the next message received. In this case, an agent would be an actor. Some actor model frameworks support both local and remote actors, known as location transparency. The underlying networking for messaging passing is abstracted away. I experimented with an early project doing exactly this in 2023, for testing an autonomous system alexsniffin/go-auto-gpt.
Nevertheless, the added complexity of such a system isn’t always justified. The nondeterministic nature of how agents operate makes creating this type of system particularly challenging, given the numerous potential points of failure. Designing a simpler local orchestration agent that delegates work to a limited number of agents would be much easier to troubleshoot and maintain. This approach would also simplify integration with other systems, such as conversational RAG (Retrieval-Augmented Generation) pipelines.
Related Research
A lot of what has been reviewed so far overlaps with the established area of research with automated planning and scheduling. It’s a branch of AI that focuses on the creation of plans or strategies to achieve specific goals or complete tasks. It optimizes autonomous decision-making and resource allocation, adapting dynamically to ensure efficient goal achievement.
Conclusion
Autonomous agents is a very exciting field in the AI space.
It’ll continue to be very challenging to build these systems but as LLMs continue to improve, so will the possibilities to build more useful autonomous systems using natural language with these patterns! Thanks for reading!